

تنظيف البيانات باستخدام لغة R البرمجية

تعد مرحلة تنظيف البيانات، واحدة من أهم محطات العمل التي تسبق مرحلة تحليل البيانات، وذلك لأن البيانات لا تأتي عادة في الصورة التي نريدها، كما أن هناك العديد من الأخطاء التي قد تحدث عند إدخال البيانات سواء تمت هذه العملية بصورة يدوية أو آلية فكلنا معرضون للوقوع في الأخطاء.
أبسط هذه الأخطاء قد تكون أخطاء إملائية في طريقة الكتابة لأحد المدخلات أو في وجود بعض المسافات الزائدة غير المرغوب فيها والتي من الممكن أن تحدث خلل في عملية استخلاص النتائج وتحليل البيانات، كذلك وجود بعض الخلايا أو الصفوف أو الأعمدة الفارغة كليًا بين مدخلات البيانات، وأخيرًا أن تأخذ البيانات تنسيقًا غير التي ينبغي أن تكون عليه كأن يكون النص منسقًا بصيغة رقمية أو العكس.
وإذا كنت اعتدت على إصلاح هذه الأخطاء باستخدام برنامج مايكروسوفت إكسل فأنت تعرف كم هو الجهد المطلوب لتنظيف البيانات، ربما يتطلب الأمر الواحد لمعالجته اتباع أكثر من خطوة للوصول إلى الصورة النهائية المرجوة، الأمر ليس مستحيلًا، لكن ماذا لو كان هناك حل أسهل بكثير يتطلب فقط كتابة عدد محدود من السطور البرمجية بلغة R، في هذه التدوينة سوف استعرض بعض المكتبات الخاصة بتنظيف البيانات و سوف نستكشف سويًا عدد من الدوال البرمجية التي ستسهل من عملية تنظيف البيانات.
أولًا: تثتيب المكتبات اللازمة لعملية تنظيف البيانات
في البداية سوف تحتاج إلى تثتيب واستدعاء ثلاث مكتبات هم: janitor ، data.validator ، dplyr وبالتأكيد مكتبة reader لقراءة ملف البيانات
لتثبيت المكتبات
install.packages("reader")install.packages("janitor")install.packages("data.validator")installed.packages("dplyr")وقد نحتاج لاحقًا لتثتيب مكتبات إضافية مثل: tidyverse و stringr
استدعاء المكتبات
library(reader)library(janitor)library(data.validator)library(dplyr)library(tidyr)library(stringr)library(tidyverse)ثانيًا: إدراج البيانات إلى محرر الكود RStudio
أفضل هذه الطريقة من خلال تبويب import dataset أسفل تبويب enviroment حيث تمكنني مباشرة من تقسيم البيانات من ملف CSV إلى أعمدة منفصلة وكذلك الصفوف التي من الممكن أن تكون بأعلى سجل البيانات و لا تحتوي على مدخلات أساسية.
يمككم إنشاء قاعدة بيانات مشابهة أو استخدام نفس قاعدة البيانات للتطبيق عليها، تجدون ملف البيانات هنا.


لاحظوا هنا ظهرت البيانات بشكل جيد، والآن من الممكن أن نضغط على زر o ليتم إدراج ملف البيانات تحت اسم df وهو الاسم الذي سوف تستخدمه بعد ذلك أثناء كتابة الكود البرمجي.
يمكننا الآن استعراض طبيعة وتنسيق محتويات الأعمدة في سجلات البيانات باستخدام str


بعض الأوامر الأخرى التي يمكن كتابتها لاستعراض البيانات والتعرف على طبيعة ونوع كل عمود بها:
| الأمر | الغرض |
| view | لمعاينة البيانات في شكل جدول |
| head | معاينة أول 6 أسطر من قاعدة البيانات، يمكن التحكم في عدد الأسطر بتحديد العدد الذي تود عرضه في المعادلة بعد علامة فصلة |
| tail | معاينة اخر 6 أسطر من قاعدة البيانات، يمكن التحكم في عدد الأسطر بتحديد العدد الذي تود عرضه في المعادلة بعد علامة فصلة |
| class(df$) | تحديد نوع عمود محدد في قاعدة البيانات |
| typeof(df$) | لتحديد نوع عمود بيانات محدد في قاعدة البيانات |
| unique(df$) | حصر قائمة فريدة في عمود محدد |
| as.factor | لتحويل البيانات إلى صيعة Factor |
| as.numeric | لتحويل تنسيق البيانات إلى صيغى عددية |
| as.character | لتحويل البيانات إلى صيغة نصية |
ثالثًا: تنظيف البيانات
بعض الأوامر الشائعة لمعالجة أسماء الأعمدة وحذف التكرارات والتخلص من المسافات الزائدة وكذلك حذف الصفوف والأعمدة الفارغة كليًا:
| الغرض | الأمر |
| إعادة تهيئة الصف الأول في البيانات الخاص بأسماء الأعمدة بصورة منظمة | ()clean_names |
| حذف الأعمدة الفارغة | ()remove_empty_cols |
| حذف الصفوف الفارغة | ()remove_empty_rows |
| إضافة عمود بالقيم الاجمالية بكل صف | ()add_totals_col |
| إضافة صف للقيم الاجمالية بكل عمود | ()add_totals_row |
| للحصول على المدخلات المكررة | ()get_dupes |
| حذف كافة الأعمدة والصفوف الفارغة كلياً | ()remove_empty |
| تحويل المدخلات في عدد من الخلايا أو الأعمدة إلى NA | convert_to_NA |
| تحويل تنسيق التاريخ من التنسيق الخاطئ إلى التنسيق الصحيح | excel_numeric_to_date |
باستخدام clean_names قمنا بتنظيف محتويات الصف الأول بسجل البيانات الذي يحتوي على أسماء الأعمدة. ومن خلال remove_empty قمنا بحذف الصفوف والأعمدة الفارغة كلياً من قاعدة البيانات

حصر القيم المكررة في سجل البيانات واستخراجها في ملف منفصل باستخدام write.csv
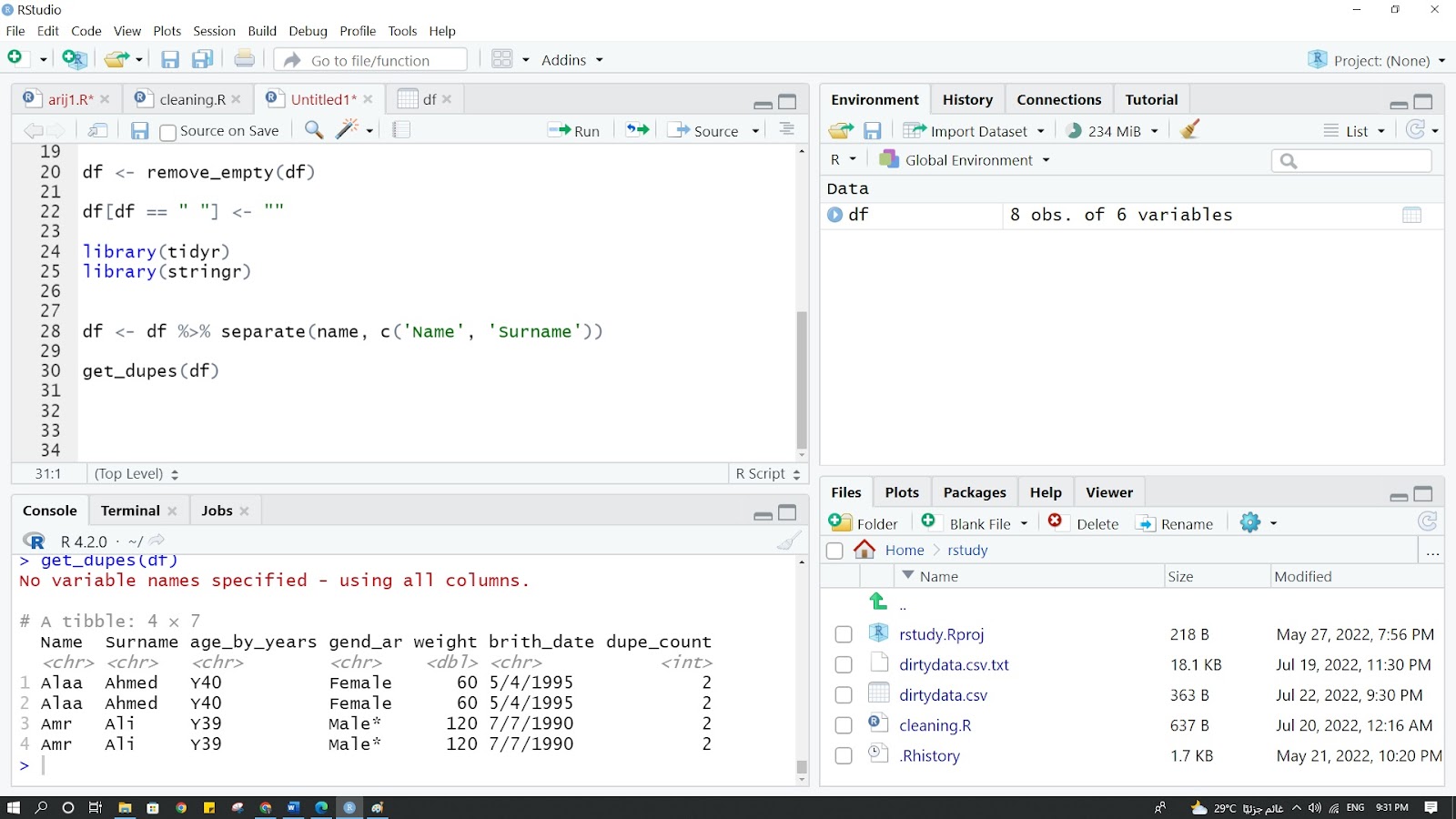
كما يمكن حفظ البيانات بعد استبعاد المدخلات المتكررة من خلال كتابة الكود التالي:
df <- df[!duplicated(df$name), ]
لا زال هناك العديد من الأخطاء التي تتطلب العمل على حلها، مثل تنسيق عمود تاريخ الميلاد واستبعاد علامة * من عمود الجندر وكذلك استبعاد حرف Y من عمود العمر، وأخيرًا اعادة تنسيق الأعمدة بشكل يتوافق مع ما تحتويه من مدخلات، لذلك أشارك معكم مجموعة من الأوامر التي تستخدم في معالجة النصوص، وادعوكم لتجربتها:
| str_length |
| str_c |
| str_sub |
| str_detect |
| str_match |
| str_count |
| str_split |
| str_to_upper |
| str_to_lower |
| str_to_title |
| str_trim |




التعليقات